
From Data to Decisions: Architecting a Self-Learning, Data-Driven Marketing Engine
Introduction
In an era where consumers generate terabytes of data every minute, marketing teams face mounting pressure to extract timely, actionable insights. According to a 2023 Forrester report, less than 25% of enterprises are realizing the full potential of their data assets in real time (https://www.forrester.com). Traditional batch-oriented approaches simply cannot keep pace with dynamic customer behaviors and market shifts. Enter the self-learning, data-driven marketing engine—an AI-powered ecosystem that continuously refines itself by ingesting live signals, retraining models, and optimizing campaigns with minimal human intervention.
This comprehensive guide delves into the principles, architecture, and step-by-step implementation of a self-learning marketing engine. You will learn how to transition from retrospective analytics to proactive decisioning, ensuring your organization stays ahead of competitors, responds nimbly to evolving customer needs, and transforms raw data into strategic opportunities.
Why Self-Learning Matters Now
- Real-Time Responsiveness. A study by McKinsey (https://www.mckinsey.com) found organizations that act on data within five days are 2× more likely to exceed revenue goals. Manual processes and siloed dashboards delay action. By continuously ingesting streaming data, your engine can trigger campaigns in seconds rather than days.
- Hyper-Personalization at Scale. Gartner predicts that by 2025, 80% of marketing campaigns will rely on real‐time personalization driven by streaming analytics (https://www.gartner.com). Self-learning models synthesize browsing behavior, purchase history, and contextual signals to craft one-to-one experiences at massive scale.
- Efficient Resource Allocation. Automated learning algorithms continually shift spend toward high-ROI channels, reducing wasted ad dollars by up to 30%, according to Statista (https://www.statista.com). This dynamic budget rebalancing ensures every dollar fuels measurable growth.
- Adaptation to Market Shocks. In a volatile economic climate, continuous learning ensures models account for seasonality, emerging trends, and unprecedented events. When consumer preferences pivot unexpectedly, your engine adapts in near real time rather than waiting for quarterly audits.
Core Architectural Components
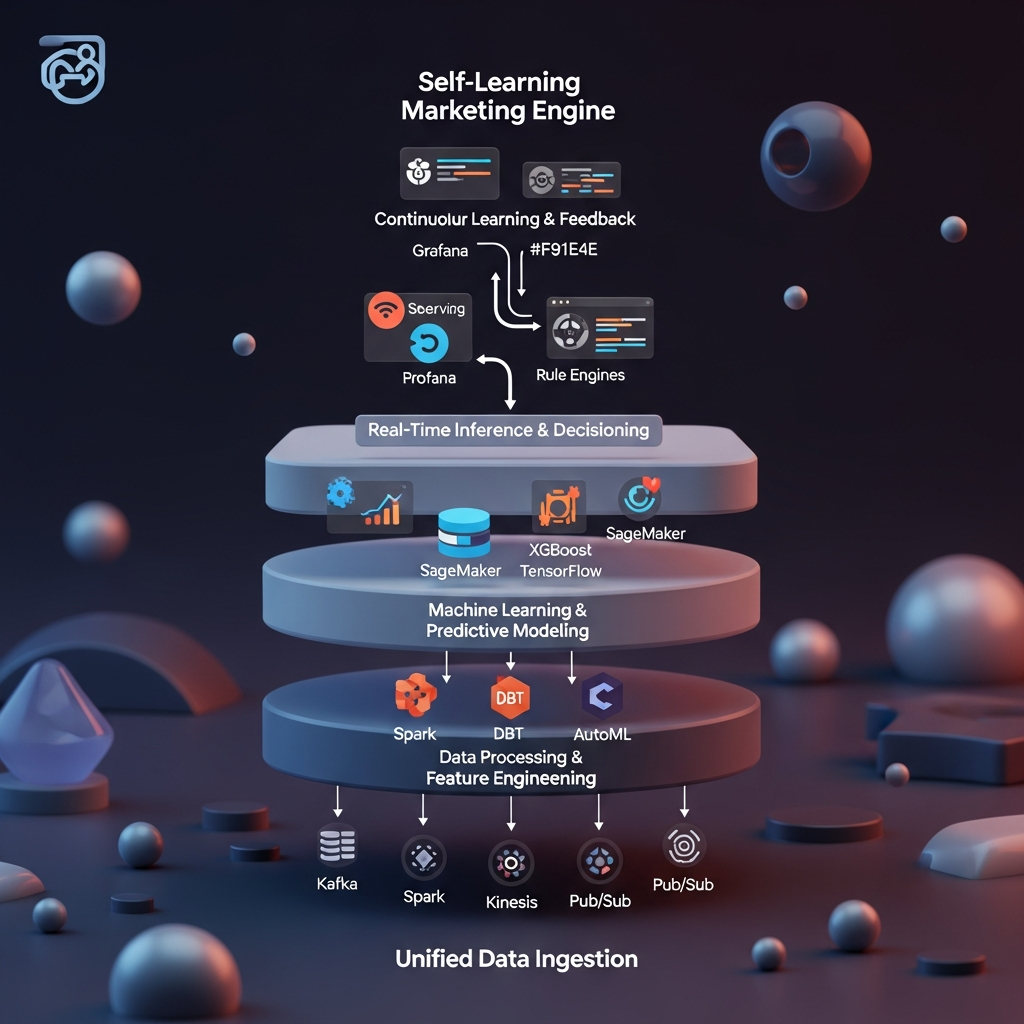
At its heart, a robust self-learning engine consists of five interconnected layers, each playing a critical role in transforming raw signals into optimized marketing actions.
1. Unified Data Ingestion
- Sources: CRM, web/mobile analytics, social streams, email platforms, point-of-sale systems, call centers.
- Tools: Apache Kafka, AWS Kinesis, Google Pub/Sub for high‐throughput event streaming.
- Best Practices: Enforce standardized schemas (Avro/JSON), use message-broker partitions to scale horizontally, implement schema registry for version control. This ensures each event—whether a click, purchase, or support ticket—is captured in the exact order and format needed for downstream processing.
2. Data Processing & Feature Engineering
- Frameworks: Apache Spark, dbt for ELT transformations, Apache Beam for unified batch/stream pipelines.
- Feature Store: Feast or Tecton for consistent offline and online feature computation.
- Key Features: Recency, frequency, monetary (RFM) metrics, behavioral sequences, propensity scores, custom customer lifetime value (CLV) indicators. By centralizing features, you guarantee reproducibility, reduce drift, and enable real-time lookups.
3. Machine Learning & Predictive Modeling
- Model Types: Gradient boosting (XGBoost, LightGBM), deep learning (TensorFlow, PyTorch), clustering (K-means, DBSCAN) for audience segmentation.
- AutoML: Google Vertex AI, H2O.ai for automated feature selection and hyperparameter tuning, accelerating time to value for non-expert teams.
- Model Governance: MLflow or Kubeflow for tracking experiments, versioning artifacts, and managing deployment lifecycle. Governance ensures every model version, data snapshot, and evaluation metric is auditable and reproducible.
4. Real-Time Inference & Decisioning
- Serving Infrastructure: KFServing on Kubernetes, AWS SageMaker Endpoints, or Google AI Platform for scalable, low-latency predictions.
- Decision Rules: Business rule engines (Drools) or custom microservices that combine predictive scores with marketing constraints (budget caps, frequency capping), ensuring compliance with brand guidelines and regulatory limits.
- Orchestration: Integration with campaign management platforms—Braze, Adobe Experience Cloud, or HubSpot—via REST APIs or Kafka topics. This tight coupling turns model output directly into live campaigns, email sends, or ad bids.
5. Continuous Learning & Feedback
- Monitoring: Prometheus and Grafana dashboards tracking latency, error rates, model accuracy, data drift, and business KPIs (CAC, LTV). Unified observability provides a single pane of glass for technical and marketing stakeholders alike.
- Retraining Triggers: Automated when accuracy drops below threshold or when significant data drift is detected using statistical tests (Population Stability Index). Automated pipelines ensure your models self-heal without manual intervention.
- Audit & Compliance: Maintain retraining logs, feature provenance, and data lineage to satisfy regulations like GDPR (https://gdpr.eu) and CCPA (https://oag.ca.gov/privacy/ccpa). A well-documented lineage is your strongest defense in an audit.
Step-by-Step Implementation Roadmap
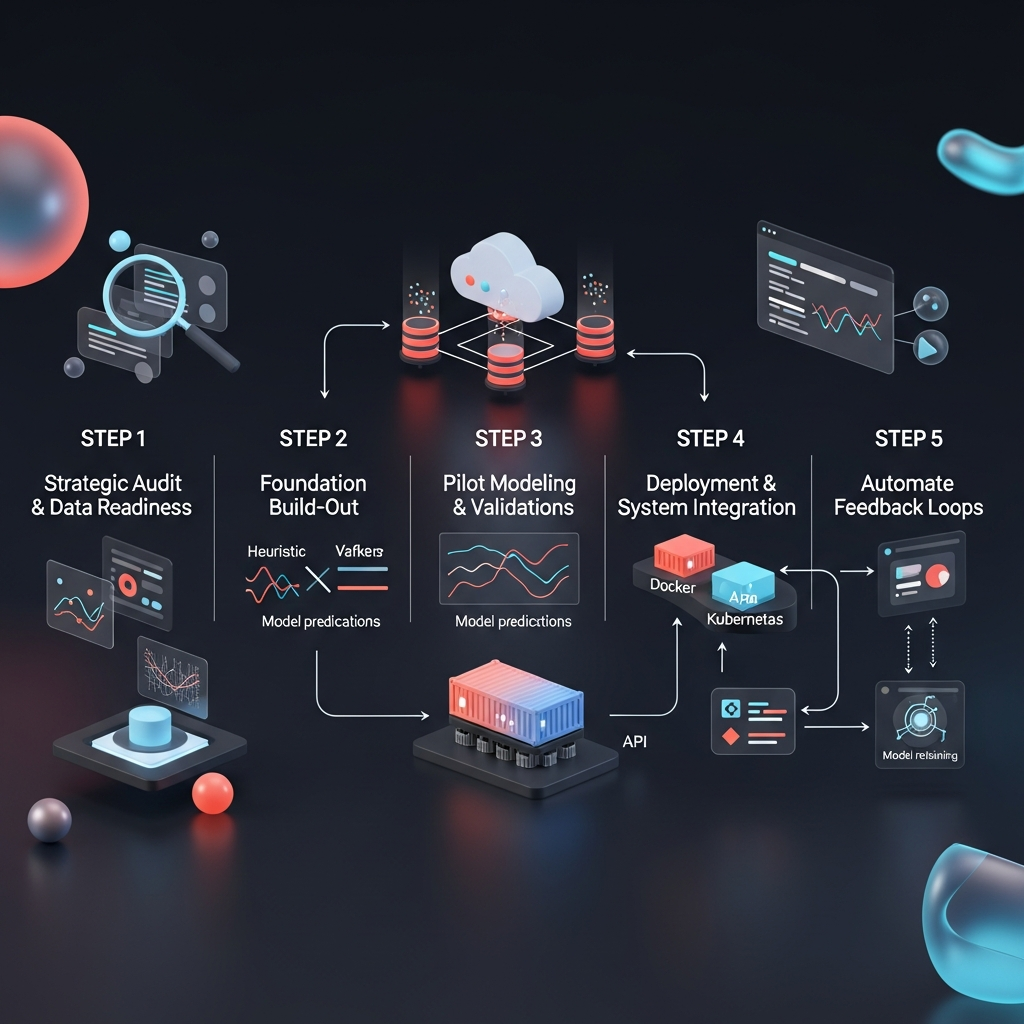
This phased approach ensures you build on solid foundations, de-risk each phase, and demonstrate value early.
Step 1: Strategic Audit & Data Readiness
- Inventory Data Assets: Catalog all inbound and historical datasets in a centralized data catalog (e.g., Amundsen, DataHub) to avoid hidden silos.
- Assess Quality & Coverage: Perform data profiling to detect missing values, inconsistent formats, and duplication. Assign data stewards to address gaps.
- Define Success Metrics: Align on business KPIs (conversion rate, average order value, churn rate) and technical benchmarks (latency < 500ms, model AUC > 0.75). Clear metrics drive focused development and measurement.
Step 2: Foundation Build-Out
- Infrastructure Selection: Choose cloud providers (AWS, GCP, Azure) or hybrid architectures based on compliance and scaling needs. Factor in global presence, data residency laws, and cost optimization.
- Data Ingestion Setup: Deploy Kafka clusters with multi-zone replication. Configure connectors (Debezium for CDC, Kinesis Data Firehose) to capture transactional changes in real time.
- Governance Framework: Implement role-based access controls (RBAC) and encryption at rest/in transit. Document data retention policies per HIPAA (if applicable) and ISO 27001 standards, ensuring enterprise-grade security.
Step 3: Pilot Modeling & Validation
- Pilot Use Case: Start with a narrowly scoped prediction—lead scoring or churn prediction. A focused pilot limits complexity and accelerates time to insight.
- Baseline Comparison: Benchmark model performance against existing heuristic rules (e.g., last three purchases, average session duration). Use lift charts and ROC curves for clear comparisons.
- Cross-Functional Reviews: Conduct feature‐engineering workshops with marketing, data science, and IT teams to validate feature definitions and labeling strategies. Collaboration builds trust and aligns priorities.
Step 4: Deployment & System Integration
- Containerization: Package inference code in Docker images; deploy to a Kubernetes cluster with autoscaling enabled. Standardized containers reduce environment drift.
- API Contracts: Define input/output schemas (JSON schema, Protobuf) and SLA expectations for request-response cycles. Clear contracts prevent integration surprises.
- End-to-End Testing: Simulate live traffic to validate data flows from ingestion through inference to action execution in downstream systems (email server, ad platform). Load testing reveals bottlenecks early.
Step 5: Automate Feedback Loops
- Monitoring Dashboards: Build Grafana or Looker dashboards displaying both technical (CPU/memory usage) and business metrics (incremental revenue, click-through rates). Unified reporting surfaces performance gaps quickly.
- Retraining Pipelines: Orchestrate weekly or event-driven retraining jobs in Apache Airflow or Prefect. Automate model promotion to production once validation criteria are met.
- Continuous Improvement: Schedule regular reviews to incorporate new data sources (e.g., IoT signals, customer support transcripts) and refine algorithms. A culture of iteration fuels long-term innovation.
Case Study: Retail Personalization Engine
A major online retailer integrated live clickstream data, inventory levels, and past purchase history to power next-product recommendations. They deployed a hybrid approach:
- Collaborative Filtering to capture community co-purchase behavior, uncovering hidden affinities between products.
- Gradient Boosting for user-specific upsell scoring, leveraging both browsing patterns and historical spend.
Results:
- 22% uplift in average order value within two months, driven by timely, context-aware suggestions.
- 15% decline in cart abandonment, as dynamic offers and personalized messages re-engaged hesitant shoppers.
- Automated model refresh every 24 hours to adapt promotions during flash sales, ensuring recommendations matched real-time inventory and demand.
Challenges & Mitigation Strategies
- Data Silos. Fragmented systems leading to incomplete customer views. Mitigation: Establish a master data management (MDM) layer and enforce a canonical data model, consolidating identities across channels.
- Model Drift. Degraded accuracy as consumer preferences shift. Mitigation: Use drift detection frameworks such as Evidently AI or custom PSI tests. Automate retraining and validate against hold-out samples to maintain performance.
- Privacy & Ethical Concerns. Overly intrusive personalization may breach consumer trust. Mitigation: Implement privacy-by-design: anonymize PII, use differential privacy techniques. Provide transparent opt-out mechanisms (https://www.ftc.gov) and clear data usage policies.
- Skill Gaps. Teams lack expertise in MLOps and real-time streaming. Mitigation: Invest in training programs (Coursera, DataCamp) and foster cross-disciplinary squads blending marketers with data engineers for hands-on collaboration.
- Change Management. Resistance to shifting from manual processes to automated decisioning. Mitigation: Secure executive sponsorship, demonstrate ROI via small pilots, and build internal evangelists through interactive workshops and success stories.
Best Practices for Long-Term Success
- Start with Narrow Pilots, Then Scale. Focus on one high-impact use case (e.g., cart abandonment) before extending to cross-sell and retention. Quick wins build momentum and credibility.
- Promote Cross-Functional Collaboration. Hold regular data-strategy standups uniting marketing, data science, IT, and legal teams under shared KPI dashboards. Alignment accelerates decision cycles.
- Emphasize Explainability & Trust. Use interpretable models (SHAP values, LIME) for high-stakes decisions like credit offers. Provide marketers with clear model rationales to foster adoption and compliance.
- Institutionalize Monitoring & Governance. Implement model cards and feature catalogs for transparency (https://www.dhrm.ohio.gov). Document every artifact and decision to support audits and continuous improvement.
- Keep Privacy at the Forefront. Regularly review consent logs, purge stale data, and maintain an up-to-date privacy policy aligned with COPPA and GDPR guidelines. Respect for customer data builds long-term trust.
Conclusion
A self-learning, data-driven marketing engine transforms how organizations engage customers—shifting from static, one-size-fits-all campaigns to dynamic, personalized experiences. By unifying streaming data ingestion, automated feature engineering, robust predictive modeling, and real-time decisioning, businesses can drive measurable uplifts in revenue, efficiency, and customer satisfaction. The key to success lies in starting small, building cross-functional momentum, and continuously refining models through automated feedback loops. Embrace this strategic framework today, and position your marketing organization at the forefront of AI-powered innovation.
References & Further Reading
- Forrester: The Future of Real-Time Analytics (2023) – https://www.forrester.com
- McKinsey: The Data-Driven Enterprise of 2025 – https://www.mckinsey.com
- Gartner: Hype Cycle for Marketing (2023) – https://www.gartner.com
- GDPR Portal – https://gdpr.eu
- Statista: Digital Advertising Spend Data – https://www.statista.com
- MLflow Open Source Documentation – https://mlflow.org
- U.S. Data.gov – https://www.data.gov
- FTC Consumer Privacy Resources – https://www.ftc.gov
- ISO 27001 Standard Overview – https://www.iso.org/isoiec-27001-information-security.html


Leave a Reply